
Guide for writing openEO User Defined Processes
Development Flow
The development of an openEO User Defined Process (UDP) starts with the creation of a process graph. This graph is a visual representation of the data processing workflow, which can be built using the openEO API and its tools. The graph consists of nodes, each representing a specific process or operation, and edges that define the flow of data between these nodes.
To start with the development of an openEO process graph, you need to select an openEO backend that provides access to the data you want to process. The backend is responsible for executing the process graph and returning the results. Once you have selected a backend, you can begin building your process graph by using the existing tools and libraries provided by openEO. These tools allow you to create, modify, and visualize your process graph in a user-friendly manner. Once you have created your process graph, you can test it on the selected openEO backend to ensure that it works as expected. This step is crucial, as it allows you to identify any issues or errors in your process graph before packaging it as a User Defined Process (UDP).
Once your process graph is complete, you can package it into a an openEO UDP, enabling it to be executed by other project members or the broader community. As a final step, you may onboard the service onto the ESA NoR, establishing a cost model and additional revenue stream for service execution.
The full development flow for creating and sharing an openEO UDP is summarized below:
- Create an Account: Create an account with an existing openEO API provider, preferably an
APEx-compliant hosting platform. This is where the UDP will be hosted. - Create the Process Graph: Develop a processing graph that represents your workflow using the existing tools provided
by your chosen. For users with an existing Python implementation, openEO offers flexibility in developing their process
graph. They can:- Utilize predefined openEO processes: map your existing Python functions to equivalent openEO operations.
- Create User Defined Functions (UDF): Create custom
functions to be executed by openEO.
- Test the Process Graph: Test the graph on your selected platform.
- Encapsulate as a UDP: The process graph is then encapsulated as a UDP, complete with metadata, as described in the
next section. - Test the UDP: Test the UDP on one or more openEO-based platforms to validate its functionality.
- Share the UDP: Once validated, the UDP is shared as a JSON definition for broader use.
- Register the UDP on ESA NoR: Define a cost model, making the service available on the ESA Network of Resources.
Keep in mind that APEx offers Algorithm Porting and Algorithm Onboarding support to help you with transforming your algorithm into an openEO UDP, onboarding it onto an APEx-compliant hosting platform, registering it in the APEx Algorithm Catalogue and its onboarding onto the ESA Network of Resources.
Creating an openEO User Defined Process
User defined processes (UDPs) are one out of two standardised options that APEx offers to publish algorithms as a service. This guide gives some concrete steps and guidelines to ensure that your UDP works well for your users. These guidelines are written with APEx in mind, but can also serve as a general guide for openEO UDPs. Where needed, recommendations and choices are made to increase uniformity across theAPEx Algorithm Catalogue.
For more background on UDP’s, or a basic tutorial on creating them, the open source Python client provides a good starting point.
Example cases
The best way to learn how to write a UDP is to look at existing examples:
max_ndvi_composite: UDP code and description.
Organizing your code
A UDP is simply a parametrized version of an openEO process graph, and as such we recommend that you use the same code to develop and test your algorithm, as you use to generate the UDP json. This ensures that your UDP is functionally equivalent to your code. Your code remains your own, and you only need to export the JSON UDP definition to share it with APEx.
It is however advisable for your UDP to link back to a public git repository if available, making your open source code more discoverable.
UDP versioning
APEx requires you to use versioning, to ensure that changes in your algorithm are clearly communicated and visible to users. A good way to do this is to use semantic versioning, which is a widely used versioning scheme.
In combination with git tags, this allows you to easily track different versions of your UDP JSON, and share immutable links to specific versions. In addition, you can also create tags that always point to the latest development or stable version.
One use case is an algorithm change that requires you to change parameters. We refer to such a change as ‘backward incompatible’, because users of the existing algorithm will not be able to switch to the new version without an update on their side. In such a case, you can create a new UDP version, and keep the old one available for users that are not ready to switch yet. Also in the UDP catalog, we recommend to keep both versions side-by-side for a certain time frame before removing the old one.
A changelog is also required, to document the changes between versions. Guidance on how to keep changelogs can be found online.
It is not mandatory to store your UDP JSON in the APEx git repository, especially if the project already maintains an open source (git) repository. The APEx repository is only a suggestion, which can be convenient if you do not have an alternative.
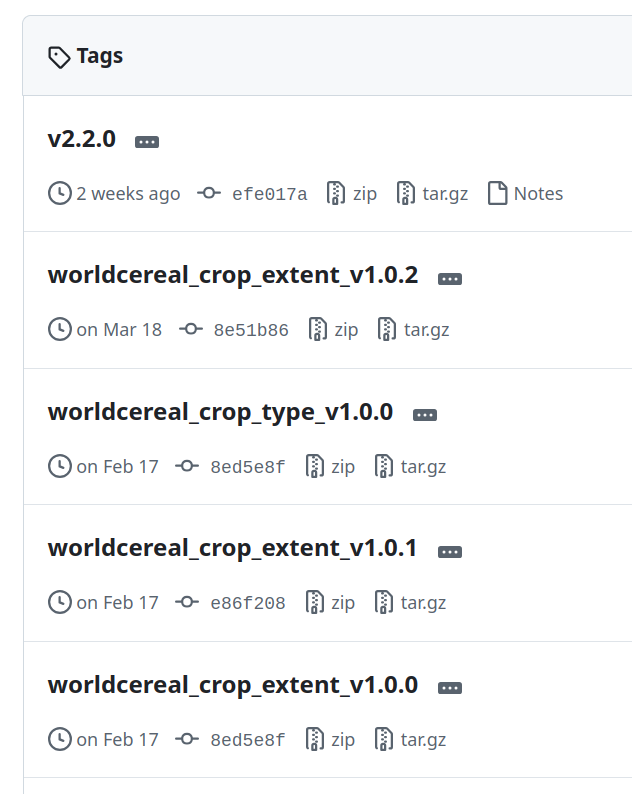
As an example, the image below shows how one project effectively used git tags to version multiple UDP’s that are hosted on GitHub. In this case, these tags exist alongside regular software version tags!
How many UDPs should I write?
Deciding on the granularity of your UDP is an important aspect of making your algorithm usable. There is no need to try and fit all possible use cases into a single UDP. Instead, consider to define pieces of functionality that can work with a limited set of parameters, and write a single UDP for each piece.
Parameter conventions
This section provides some recommendations on how to name parameters in your UDP. While these are not mandatory, we recommend to consider them to avoid that users of the APEx Algorithm Catalogue would be confused by variations in process parameter names.
Please let us know if you encounter a parameter that could use a convention, and we will add it here.
Spatial filtering
Any algorithm requires spatial filtering, so we can make the life of our users easier if we all use the same naming.
In the standard openEO processes load_collection and load_stac, spatial filtering done through the argument called spatial_extent, which support multiple types: a bounding box object, an inline GeoJSON object, a vector cube, or it can even be left empty (null). For maximum flexibility, compatibility and the best user experience, we recommend to perform spatial filtering in your algorithm:
- directly in
load_collection/load_stac(instead of separatefilter_bbox/filter_spatialprocesses) - using a parameter named
spatial_extent(unless there are good reasons otherwise) spatial filtering in these processes, and also usespatial_extentas the parameter name unless there are good reasons otherwise.
If you pass on the spatial_extent parameter to all load_collection processes in your UDP, then it is also allowed to perform filtering using vector data. This conveniently allows for advanced spatial filtering use cases!
The Python client has a convenience function called Parameter.spatial_extent() to create this parameter when building your UDP via Python.
Temporal filtering
For openEO processes that support arbitrary temporal ranges, we recommend using temporal_extent as the name of parameter to ensure consistency with other openEO processes, such as load_collection.
Many cases also require a time range with a fixed length. In such a case, you can allow to specify only the start or end date, and use the date_shift process to construct the second date in the temporal interval, ensuring a fixed length. This avoids faulty user input.
Avoid use of save_result
Most openEO process graphs end in a save_resultprocess. However, this is not recommended for UDPs, as the user may want to perform additional processing steps before generating the result. So having a DataCube (raster or vector) as the final output is recommended unless if your service wants to enforce specific settings on how the output is to be generated.
Include default parameters within the UDP
Via the [1] extension, platform specific parameters (also known as job options) can be included directly in the process definition. While the primary recommendation is to avoid using platform specific parameters, it is nevertheless a very good idea to include them when they are necessary.
UDP documentation
The description of your UDP should be quite extensive if you want users to be able to easily assess if it’s suitable for them.
We recommend including these sections:
- Description: A short description of what the algorithm does.
- Performance characteristics: Information on the computational efficiency of the algorithm. Include a relative cost if available.
- Examples: One or more examples of the algorithm in action, using images or plots to show a typical result. Point to a STAC metadata file with an actual output asset to give users full insight into what is generated.
- Literature references: If your algorithm is based on scientific literature, provide references to the relevant publications.
- Known limitations: Any known limitations of the algorithm, such as the type of data it works best with, or the size of the area it can process efficiently.
- Known artifacts: Use images and plots to clearly show any known artifacts that the algorithm may produce. This helps users to understand what to expect from the algorithm.
A template is available to help you structure your documentation.
Integrating your openEO process (UDP) in APEx
Once you have an eligible openEO process, you are ready to integrate it in APEx. At this point, you should have an HTTP link to a JSON document that defines the process, and is publicly accessible. The most common way to do this is to store it in a public git repository. Tagging a release is a good way to ensure that the link remains stable.
Registering your process
Next, you will need to upload a generic JSON to the APEx Algorithm Catalogue to register your process. For now, this is done by creating a pull request in the APEx Algorithm Catalogue GitHub repository.
An example json is provided below. The properties to modify are listed here:
- id: a unique identifier for your process
- created and updated timestamps
- title: a descriptive title
- description: a detailed description of the process
- contacts: a list of contacts, with at least one principal investigator
- keywords: a list of free form keywords
- themes: Applicable concepts from a scheme. Concepts can be found in the ESA Data Ontology
- license: the license under which the process is published. You can use the SPDX license list for this. Proprietary licenses are possible, within the terms of your ESA project.
The links section is crucial, the following “rel” values are mandatory:
- openeo-process: exactly one link to the JSON document that defines the process
- service: at least one link to an openEO backend that is able to execute the process
- example: at least one link to a STAC metadata file that shows the output of the process
The type field of these links should be set to application/json. Please provide a descriptive title for each link, allowing to understand what the link is about.
{
"id": "max_ndvi_composite",
"type": "Feature",
"conformsTo": [
"http://www.opengis.net/spec/ogcapi-records-1/1.0/req/record-core",
"https://apex.esa.int/core/openeo-udp"
],
"properties": {
"created": "2024-09-06T00:00:00Z",
"updated": "2024-09-06T00:00:00Z",
"type": "service",
"title": "Max NDVI Composite based on Sentinel-2 data",
"description": "A compositing algorithm for Sentinel-2 L2A data, ranking observations by their maximum NDVI.",
"cost_estimate": 1,
"cost_unit": "platform credits per km\u00b2",
"keywords": [
"vegetation",
"ndvi
],
"language": {
"code": "en-US",
"name": "English (United States)"
},
"languages": [
{
"code": "en-US",
"name": "English (United States)"
}
],
"contacts": [
{
"name": "Jeroen Dries",
"position": "Researcher",
"organization": "VITO",
"links": [
{
"href": "https://www.vito.be/",
"rel": "about",
"type": "text/html"
},
{
"href": "https://github.com/jdries",
"rel": "about",
"type": "text/html"
}
],
"contactInstructions": "Contact via VITO",
"roles": [
"principal investigator"
]
},
{
"name": "VITO",
"links": [
{
"href": "https://www.vito.be/",
"rel": "about",
"type": "text/html"
}
],
"contactInstructions": "SEE WEBSITE",
"roles": [
"processor"
]
}
],
"themes": [ {
"concepts": [
{ "id": "NORMALIZED DIFFERENCE VEGETATION INDEX (NDVI)", url: "https://gcmd.earthdata.nasa.gov/kms/concept/2297a00a-80f5-466e-b28e-b9ca42562d3f?format=json" },
{ "id": "Sentinel-2 MSI", "url": "https://gcmd.earthdata.nasa.gov/kms/concept/fc57a9a0-a287-4bcf-a517-20811b55596b?format=json" }
],
"scheme": "https://gcmd.earthdata.nasa.gov/kms/concepts/concept_scheme/sciencekeywords"
}],
"formats": [
"GeoTiff", "netCDF"
],
"license": "CC-BY-4.0"
},
"linkTemplates": [],
"links": [
{
"rel": "application",
"type": "application/json",
"title": "openEO Process Definition",
"href": "https://raw.githubusercontent.com/ESA-APEx/apex_algorithms/max_ndvi_composite/openeo_udp/examples/max_ndvi_composite/max_ndvi_composite.json"
},
{
"rel": "service",
"type": "application/json",
"title": "CDSE openEO federation",
"href": "https://openeofed.dataspace.copernicus.eu"
},
{
"rel": "example-output",
"type": "application/json",
"title": "Example output",
"href": "https://radiantearth.github.io/stac-browser/#/external/s3.waw3-1.cloudferro.com/swift/v1/APEx-examples/max_ndvi_denmark/collection.json"
},
{
"rel": "webapp",
"type": "text/html",
"title": "OpenEO Web Editor",
"href": "https://editor.openeo.org/?wizard=UDP&wizard~process=max_ndvi_composite&wizard~processUrl=https://raw.githubusercontent.com/ESA-APEx/apex_algorithms/main/algorithm_catalog/vito/max_ndvi_composite/openeo_udp/max_ndvi_composite.json&server=https://openeofed.dataspace.copernicus.eu"
}
]
}
Defining a validation & benchmark scenario
APEx has the capability to automatically check if your openEO process is working as expected, and if the cost for specific scenarios is sufficiently stable over time. This is a very important feature to avoid that your users have a bad experience. It also helps to ensure that the openEO backend provider you selected is performing well, and that changes to the backend service do not break your process.
APEx requires at least one benchmark scenario, to be able to correctly mark processes that are (temporarily)unavailable. When this happens, the ‘principal investigator’, as defined in the JSON of the previous step, is informed, allowing to take action as desired.
The benchmark scenarios are defined as JSON files in the benchmark_scenarios folder of your service. The schema of these files is defined (as JSON Schema)in the schema/benchmark_scenario.json file.
Example benchmark definition:
[
{
"id": "max_ndvi",
"type": "openeo",
"backend": "openeofed.dataspace.copernicus.eu",
"process_graph": {
"maxndvi1": {
"process_id": "max_ndvi",
"namespace": "https://raw.githubusercontent.com/ESA-APEx/apex_algorithms/f99f351d74d291d628e3aaa07fd078527a0cb631/openeo_udp/examples/max_ndvi/max_ndvi.json",
"arguments": {
"temporal_extent": ["2023-08-01", "2023-09-30"],
...
},
"result": true
}
},
"reference_data": {
"job-results.json": "https://s3.example/max_ndvi.json:max_ndvi:reference:job-results.json",
"openEO.tif": "https://s3.example/max_ndvi.json:max_ndvi:reference:openEO.tif"
}
},
...
]Note how each benchmark scenario references:
- the target openEO backend to use.
- an openEO process graph to execute. The process graph will typically just contain a single node pointing with the
namespacefield to the desired process definition at a URL, following the remote process definition extension. The URL will typically be a raw GitHub URL to the JSON file in theopeneo_udpfolder, but it can also be a URL to a different location. - reference data to which actual results should be compared.
Defining and updating benchmark reference data
A benchmark scenario should define reference data, with which the actual results of benchmark runs should be compared. The reference_data field of a benchmark scenario is a JSON object that maps each of the openEO batch job result assets (by asset name) to a URL where the reference data can be found, e.g.
{
"reference_data": {
"job-results.json": "https://s3.example/max_ndvi.json:max_ndvi:reference:job-results.json",
"openEO.tif": "https://s3.example/max_ndvi.json:max_ndvi:reference:openEO.tif"
}
}The reference data URLs should be publicly accessible. For example, as suggested by the example, as S3 storage URLs. While you are free to manage the hosting of the reference data yourself, it is recommended to just rely on the APEx infrastructure and workflows as follows.
The APEx benchmarking system will automatically store the actual results (if any)of failed benchmark runs in a public S3 bucket managed by APEx, to allow post-mortem inspection of these results. The URLs of these actual result assets will be reported in the benchmark report and can be used directly as reference data URLs for subsequent benchmark runs. Of course, make sure the actual results are properly validated and acceptable under your standards before using them as reference data for future benchmark runs.
Initial reference data
When you are initially defining a benchmark scenario, you may not have the full set of expected reference data and metadata yet. In this case, it’s fine to leave out the reference_data field, make it an empty mapping object, or use invalid placeholder URLs. When the benchmark scenario is executed and the underlying openEO batch job finishes successfully, the actual batch job results will be downloaded first. Next, the full actual result set will be compared to the reference data, which will be missing or incomplete, causing the benchmark run to fail. This failure will trigger the storage of the actual results in the APEx S3 bucket, and the corresponding URLs will be reported in the (pytest based) benchmark run output of the corresponding GitHub workflow run. It will look like this:
-------------------- `upload_assets` stats: {'uploaded': 2} --------------------
- tests/test_benchmarks.py::test_run_benchmark[max_ndvi]:
- 'actual/openEO.tif' uploaded to 'https://s3.example/gh-1234!max_ndvi!actual/openEO.tif'
- 'actual/job-results.json' uploaded to 'https://s3.example/gh-1234!max_ndvi!actual/job-results.json'These URLs can be used as reference data URLs for subsequent benchmark runs.
Updating reference data
When an algorithm is updated, or the underlying data changes for some reason, a benchmark scenario might start to fail on the reference data comparison. Updating the reference data is practically the same as defining it initially:look up the URLs of the actual results in the benchmark report, validate these new results, and update the benchmark scenario with the new reference data URLs.